单例设计模式
设计模式:
·设计模式是前人工作的总结和提炼,通常,被人们广泛流传的设计模式都是针对某一特定问题的成熟解决方案
·使用设计模式是为了可重用代码、让代码更容易被他人理解、保证代码可靠性
单例设计模式:
·目的——让类创建的对象,在系统中只有唯一的一个实例
·每一次执行类名()返回的对象,内存地址是相同的
class MusicPlayer: |
效果图:
对比图:
初始化方法只执行一次:class MusicPlayer:
# 记录第一个被创建对象的引用
instance=None
# 记录是否执行过初始化动作
init_flag=False
def __new__(cls,*args,**kwargs):
if cls.instance is None:
cls.instance=super().__new__(cls)
return cls.instance
def __init__(self):
if MusicPlayer.init_flag:
return
print("初始化播放器")
MusicPlayer.init_flag=True
player1=MusicPlayer()
print(player1)
player2=MusicPlayer()
print(player2)
效果图:
对比图: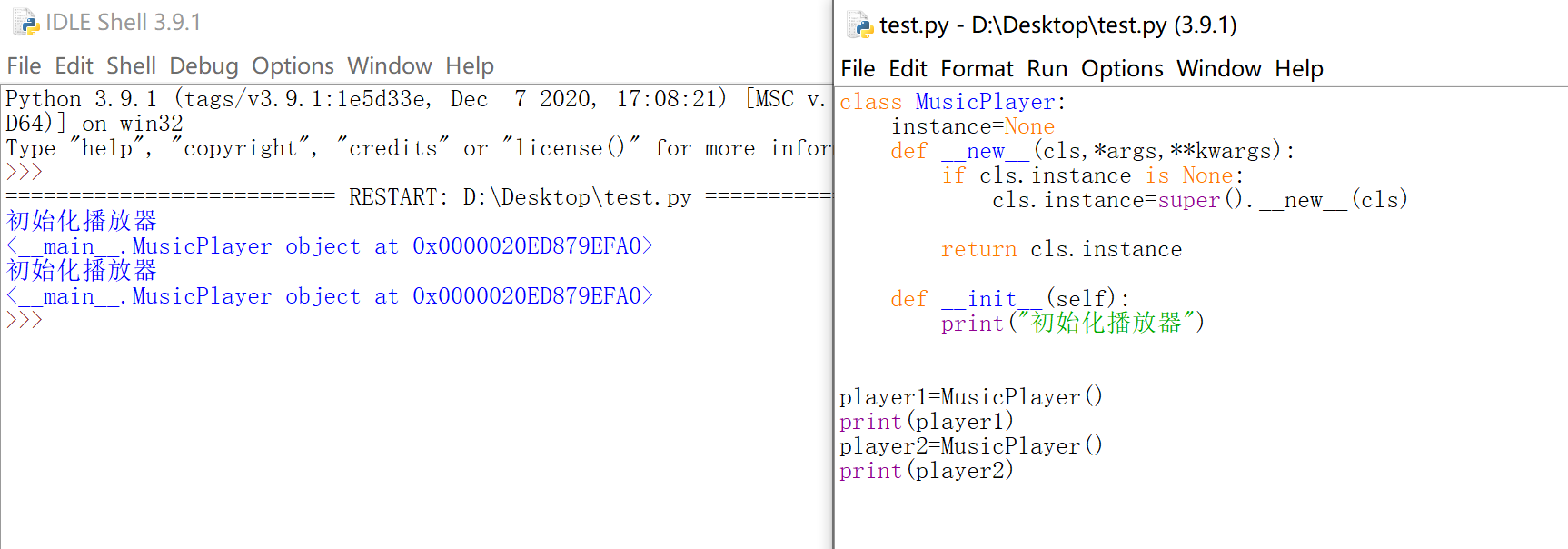
异常
简单的异常捕获语法
try:
(缩进)尝试执行的代码
except:
(缩进)出现错误的处理
try: |
效果图:
异常捕获完整语法
语法:try:
# 尝试执行的代码
pass
except 错误类型1:
# 针对错误类型1,对应的代码处理
pass
except 错误类型2:
# 针对错误类型2,对应的代码处理
pass
except(错误类型3,错误类型4):
# 针对错误类型3和4,对应的代码处理
pass
except Exception as result:
# 打印错误信息
print(“未知错误 %s”% result)
else:
# 没有异常才会执行的代码
pass
finally:
# 无论是否有异常,都会执行的代码
print(“无论是否有异常,都会执行的代码”)
说明:
(1)result是变量名,可以改为其他名称
(2)else只有在没有异常才会执行代码
(3)finally无论是否有异常,都会执行代码
try: |

抛出raise异常
def input_password(): |
效果图1(自抛不捕):
效果图2(自抛自捕):
文件操作
读写文件
file=open("随手记.txt",encoding="UTF-8") |
说明:
(1)注意编码,若不用UTF-8可能报错
(2)如果忘记关闭文件,会造成系统资源消耗,而且会影响到后续对文件的访问
效果图:
一些参数:
- r:只读,若文件不存在,会抛出异常
- w:只写,若文件存在,会覆盖原有文件;若文件不存在会新建文件
- a:追加,若文件存在,会将文件指针放在文件结尾;若文件不存在会新建文件
- r+:读写,若文件不存在,会抛出异常
- w+:读写,若文件存在,会覆盖原有文件;若文件不存在会新建文件
- a+:读写,若文件存在,会将文件指针放在文件结尾;若文件不存在会新建文件
- wb:以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。
- wb+:以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。
效果图:

readline方法
read方法默认把文件内容一次性存取到内存
如果文件太大,对内存的占用会非常严重
readline方法一次读取一行,并自动换行
方法执行后,文件指针会移到下一行,准备再次读取
读取大文件的正确姿势:# 打开文件
file=open("123.txt",encoding="UTF-8")
while True:
# 读取一行内容
text=file.readline()
# 判断是否读到内容
if not text:
break
# 每读取一行的末尾已经有了一个“\n”
print(text,end="")
# 关闭文件
file.close()
效果图:
案例:复制文件
小文件复制:# 打开文件
file_read=open("README.txt",encoding="UTF-8")
file_write=open("README[副本].txt","w",encoding="UTF-8")
# 读写文件
text=file_read.read()
file_write.write(text)
# 关闭文件
file_read.close()
file_write.close()
大文件复制:# 打开文件
file_read=open("README.txt",encoding="UTF-8")
file_write=open("README[副本].txt","w",encoding="UTF-8")
# 读写文件
while True:
text=file_read.readline()
if not text:
break
file_write.write(text)
# 关闭文件
file_read.close()
file_write.close()
说明:第二次打开文件才会覆盖,只要不关闭文件,文件指针同样会移动到下一行
文件/目录管理操作

正则表达式
如果正则表达式中多出使用了圆括号进行分组的话。
在使用findall方法匹配结果就会只有分组的结果(即括号内表达式匹配的内容),而不是整个表达式所匹配的内容。
如果使用search方法匹配,对返回的Matcher对象调用group()方法可以获取完整的结果。但是在需要匹配多个结果时,还得用findall
BeautifulSoup
对象的实例化
(1)将本地的html文档中的数据加载到该对象中fp=open("./test.html","r",encoding="utf-8")
soup=BeautifulSoup(fp,"lxml")
(2)将互联网上获取的数据页面源码加载到该对象中page_text=response.text
soup=BeautifulSoup(page_text,"lxml")
提供的用于数据解析的方法和属性
(1)soup.tagName:返回的是文档中第一次出现的tagName对应的标签
(2)soup.find:
- find(“tagName”):等同于soup.tagName
- 属性定位:soup.find(“div”,class_/id/attr=”song”)
(3)soup.find_all(“tagName”):返回符合要求的所有标签(列表形式返回)
(4)select: - select(“某种选择器(id,class,标签…选择器)”),返回的是一个列表
- 层级选择器:
soup.select(“.tang>ul>li>a”):“>”表示的是一个层级
soup.select(“.tang>ul a”):空格表示的是多个层级
(5)获取标签之间的文本数据: - soup.a.text/string/get_text()
- text/get_text():可以获取某一个标签中的所有文本内容
- string:只可以获取该标签下面直系的文本内容
(6)获取标签中属性值: - soup.a[“href”]
xpath
1.xpath解析原理:
(1)实例化一个etree对象,且需要将被解析的页面源码数据加载到该对象中
(2)调用etree对象中xpath方法结合着xpath表达式实现标签的定位和内容的捕获
2.实例化一个etree对象:from lxml import etree
(1)将本地的html文件中的源码数据加载到etree对象中:
etree.parse(filePath)
(2)可以将从互联网上获取的源码数据加载到该对象中
etree.HTML(page_text)
3.xpath表达式
(1)/:表示的是从根节点开始定位。表示的是一个层级
(2)//:表示的是多个层级。可以从任意位置开始定位
(3)属性定位://div[@class=”song”]
(4)索引定位://div[@class=”song”]/[3]索引是从1开始的
(5)取文本:
- /text()获取的是标签中直系的文本内容
- //text()标签中非直系的文本内容(所有的文本内容)
(6)取属性:/@attrName ===>img/@src
selenium模块
基本使用
发起请求:get(url)
标签定位:find系列方法(find_element_by_xpath,find_element_by_class_name,find_element_by_id……)
标签交互:send_keys(‘xxx’)
执行js程序:excute_script(‘jsCode’)
前进,后退:back(),forward()
关闭浏览器:quit()
例:from selenium import webdriver
from time import sleep
bro=webdriver.Firefox(executable_path='geckodriver')
# 请求url
bro.get('https://www.taobao.com/')
# 定位输入框
search_input=bro.find_element_by_id('q')
# 输入文字
search_input.send_keys('iphone')
sleep(2)
# 执行一组js程序
bro.execute_script('window.scrollTo(0,document.body.scrollHeight)')
sleep(2)
# 定位搜索按钮
btn=bro.find_element_by_xpath('//*[@id="J_TSearchForm"]/div[1]/button')
# 点击按钮
btn.click()
sleep(2)
# 跳转别的页面
bro.get('https://www.baidu.com')
sleep(2)
# 后退
bro.back()
sleep(2)
# 前进
bro.forward()
sleep(2)
# 关闭浏览器
bro.quit()
selenium处理iframe
如果定位的标签存在于iframe标签之中,则必须使用switch_to.iframe(id)
动作链(拖动):from selenium.webdriver import ActionChains
实例化一个动作链对象:action=ActionChains(bro)
click_and_hold(div):长按且点击操作
move_by_offset(x,y):x表示水平距离,y表示垂直距离,单位像素
perform():让动作链立即执行
action.release():释放动作链对象






