需求:
爬取国家药品监督管理总局中基于中华人民共和国化妆品生产许可证相关数据(http://scxk.nmpa.gov.cn:81/xk/)
主页面如下: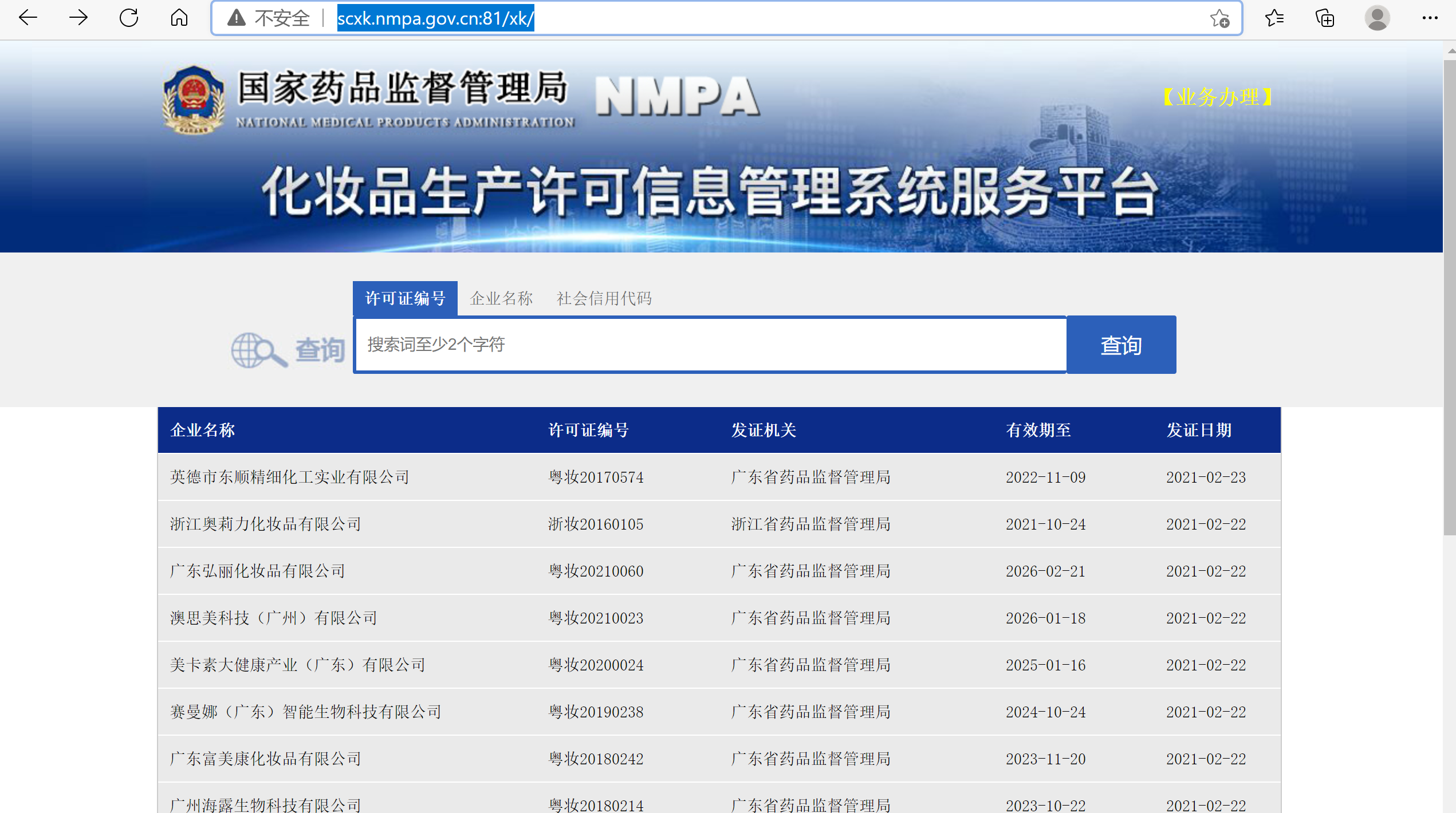
子页面如下: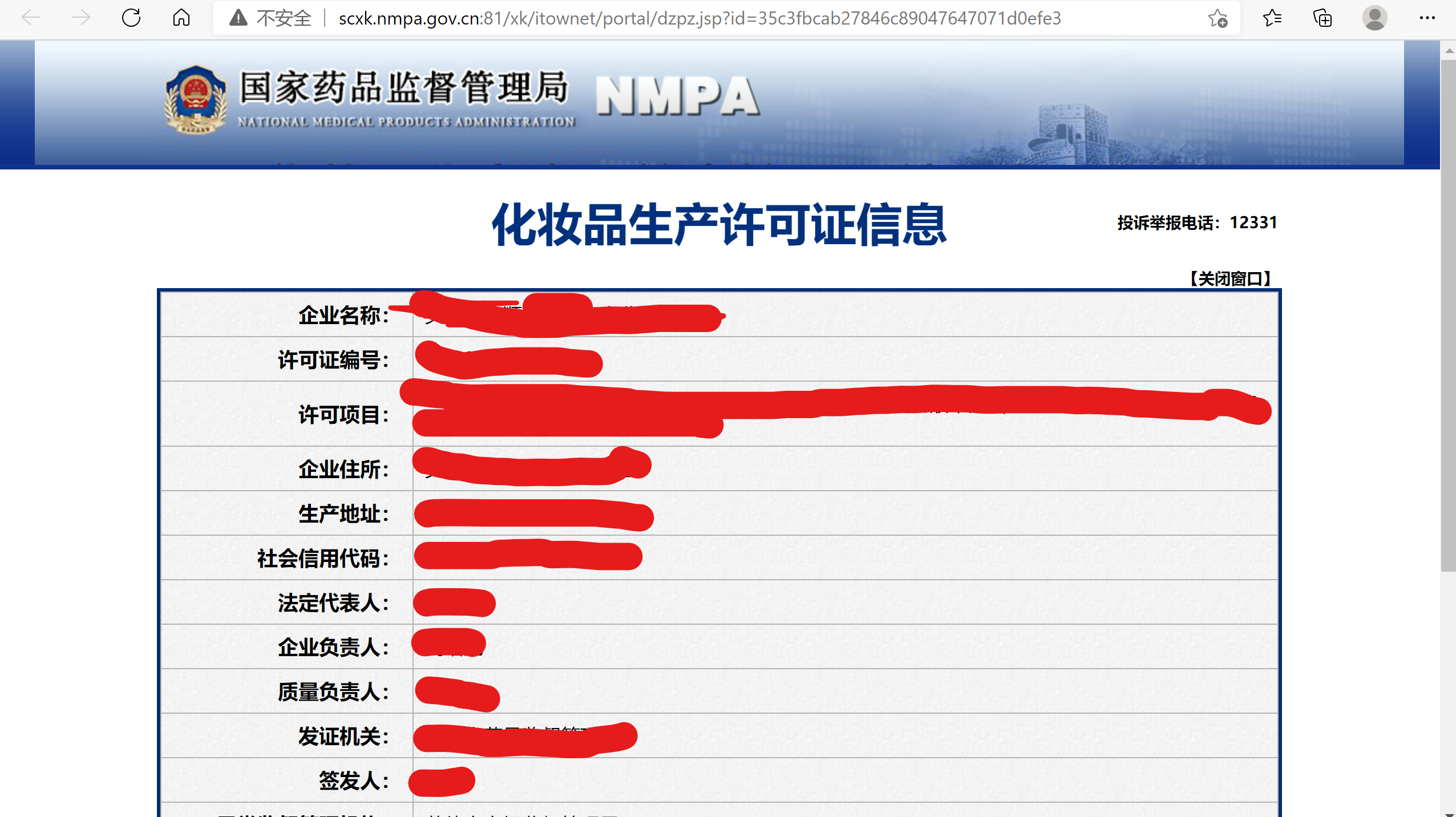
即爬取所有上图信息
方法一:
脚本:import requests
import json
url="http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsList"
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36 Edg/88.0.705.74"}
id_list=[]#存储企业id
for page in range(1,6):
#这里爬取1-5页作为示例,若需爬取所有,将循环范围扩大即可
data={ "on": "true",
"page": str(page),
"pageSize": "15",
"productName": "",
"conditionType": "1",
"applyname": ""}
index_json=requests.post(url,data=data,headers=headers).json()
for i in index_json["list"]:
id_list.append(i["ID"])
#获取企业详情数据
all_data=[]
url2="http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsById"
for i in id_list:
data={"id":i}
detail=requests.post(url2,data=data,headers=headers).json()
all_data.append(detail)
#持久化存储
file=open("AllData.json","w",encoding="UTF-8")
json.dump(all_data,fp=file,ensure_ascii=False,indent=4)
file.close()
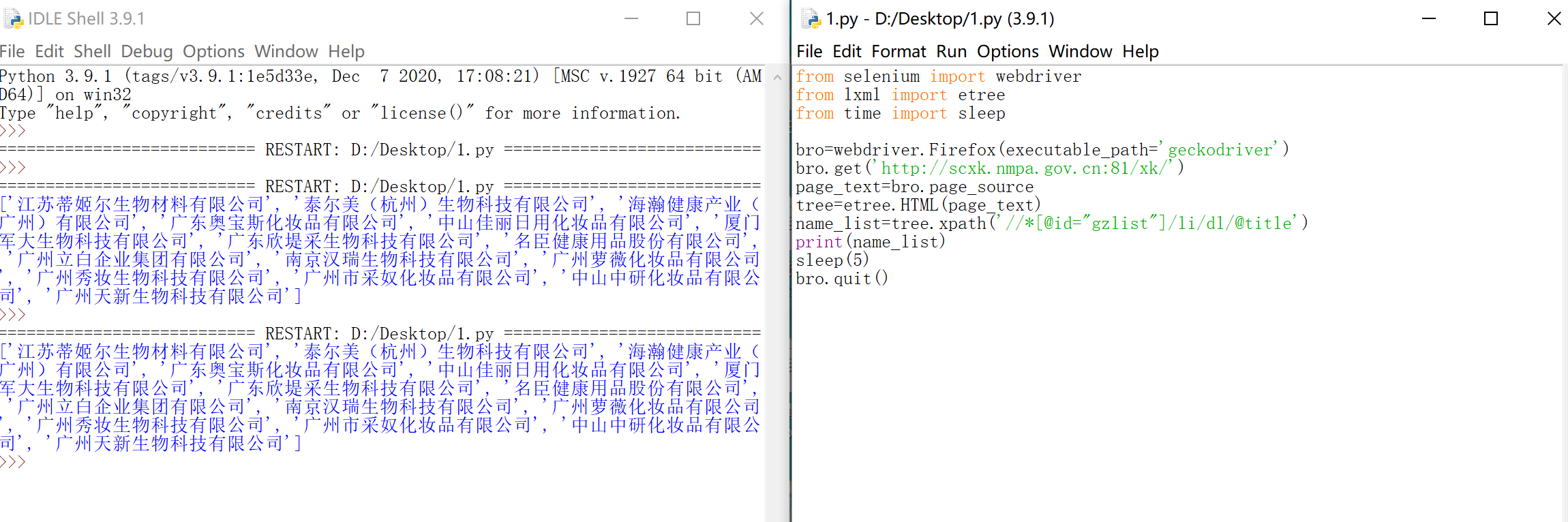
爬取效果如下: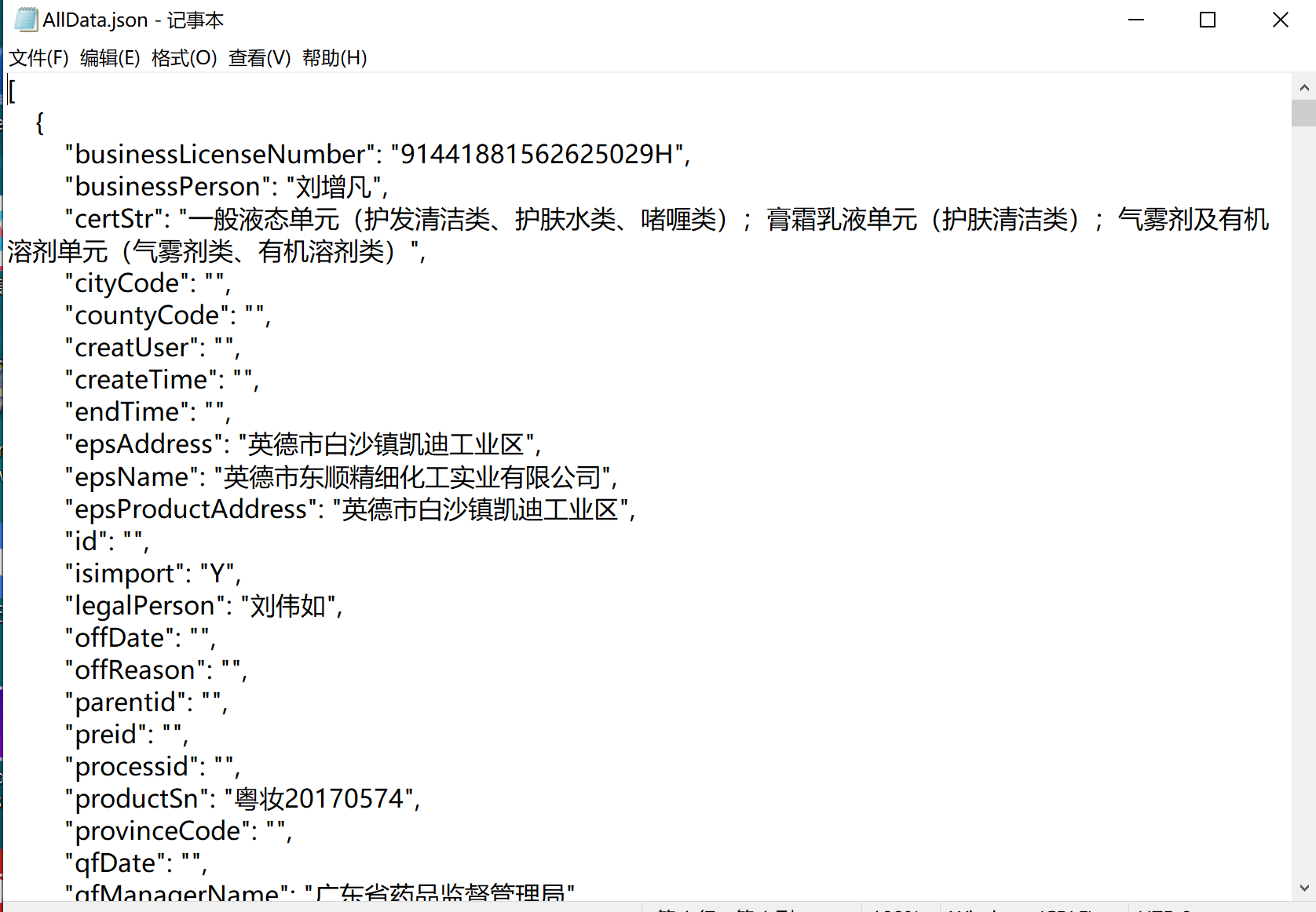
方法二:
利用selenium模块
脚本:from selenium import webdriver
from lxml import etree
from time import sleep
# geckodriver是火狐的驱动程序
bro=webdriver.Firefox(executable_path='geckodriver')
bro.get('http://scxk.nmpa.gov.cn:81/xk/')
page_text=bro.page_source
tree=etree.HTML(page_text)
name_list=tree.xpath('//*[@id="gzlist"]/li/dl/@title')
# 这里打印出来意思一下
print(name_list)
sleep(5)
bro.quit()
效果图: