58二手房
需求:
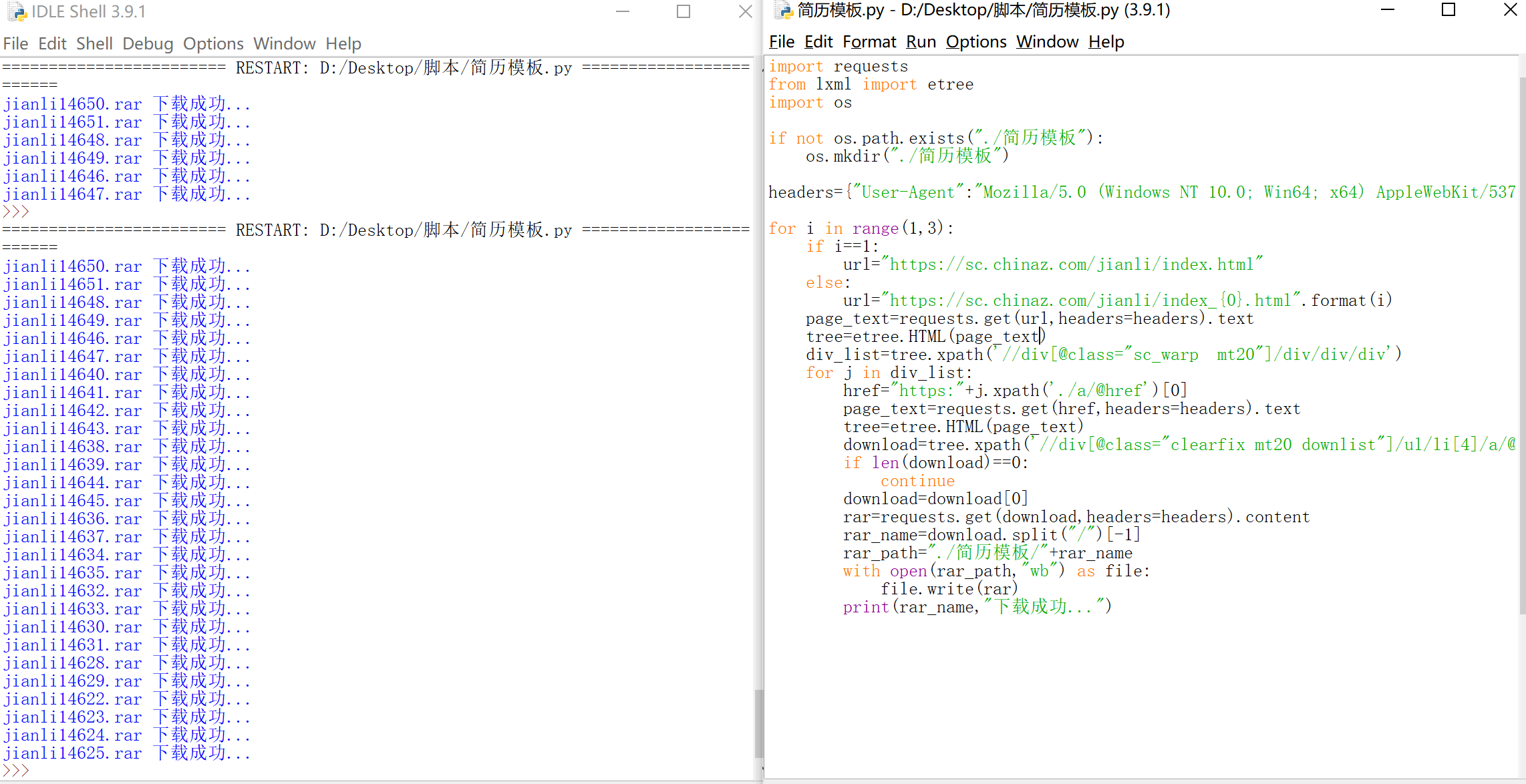
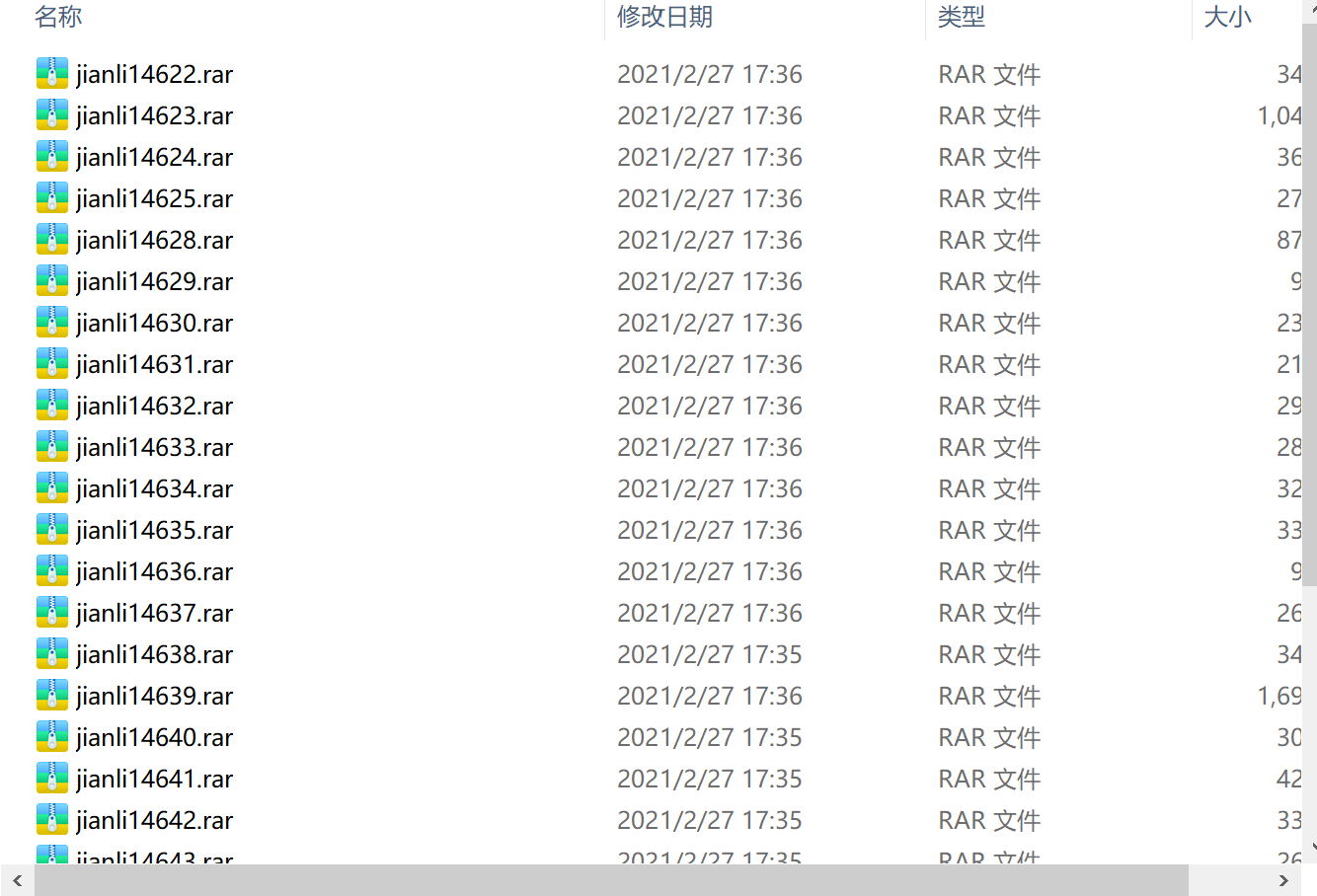
爬取58二手房数据(标题,价格)
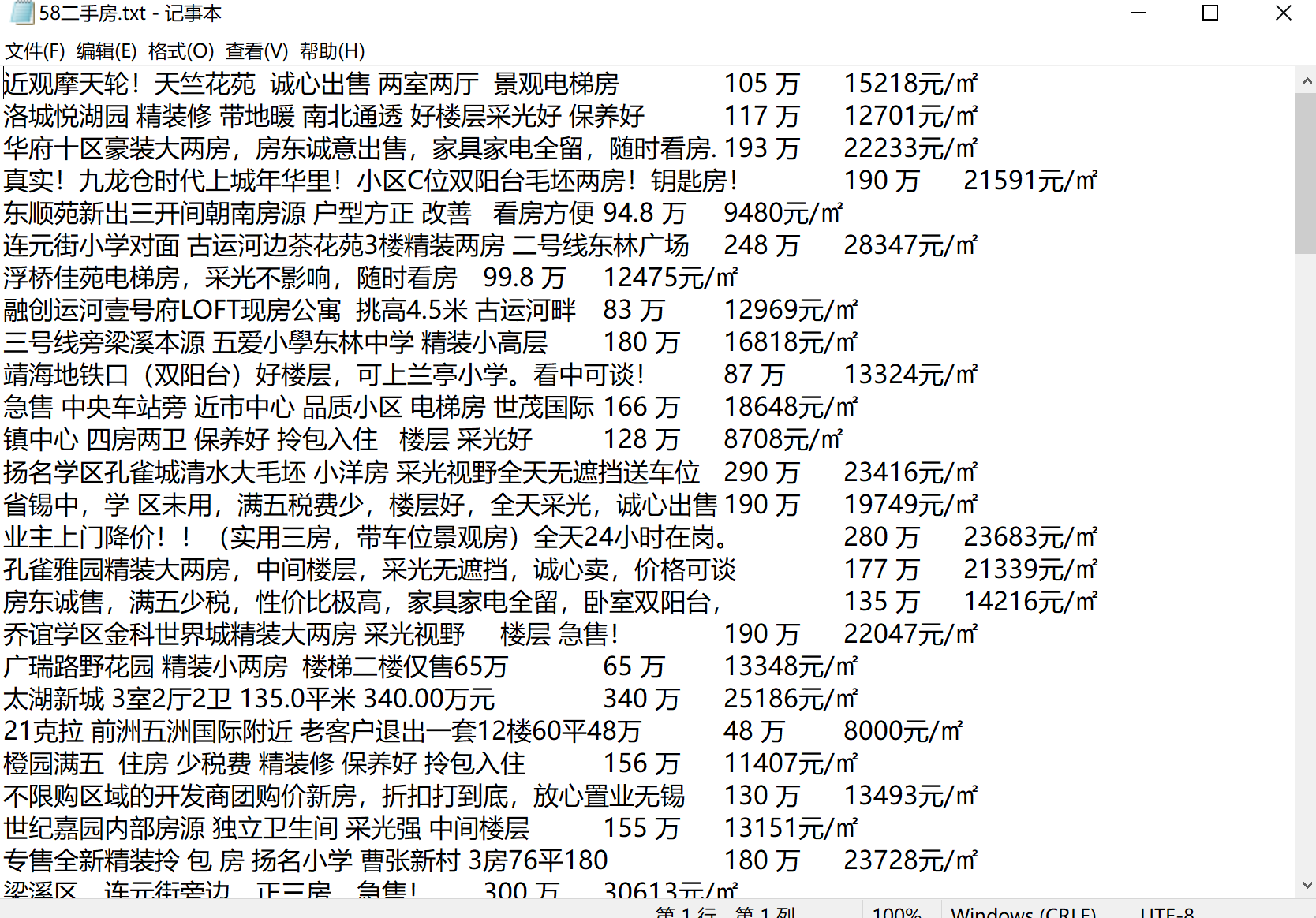
如图所圈数据: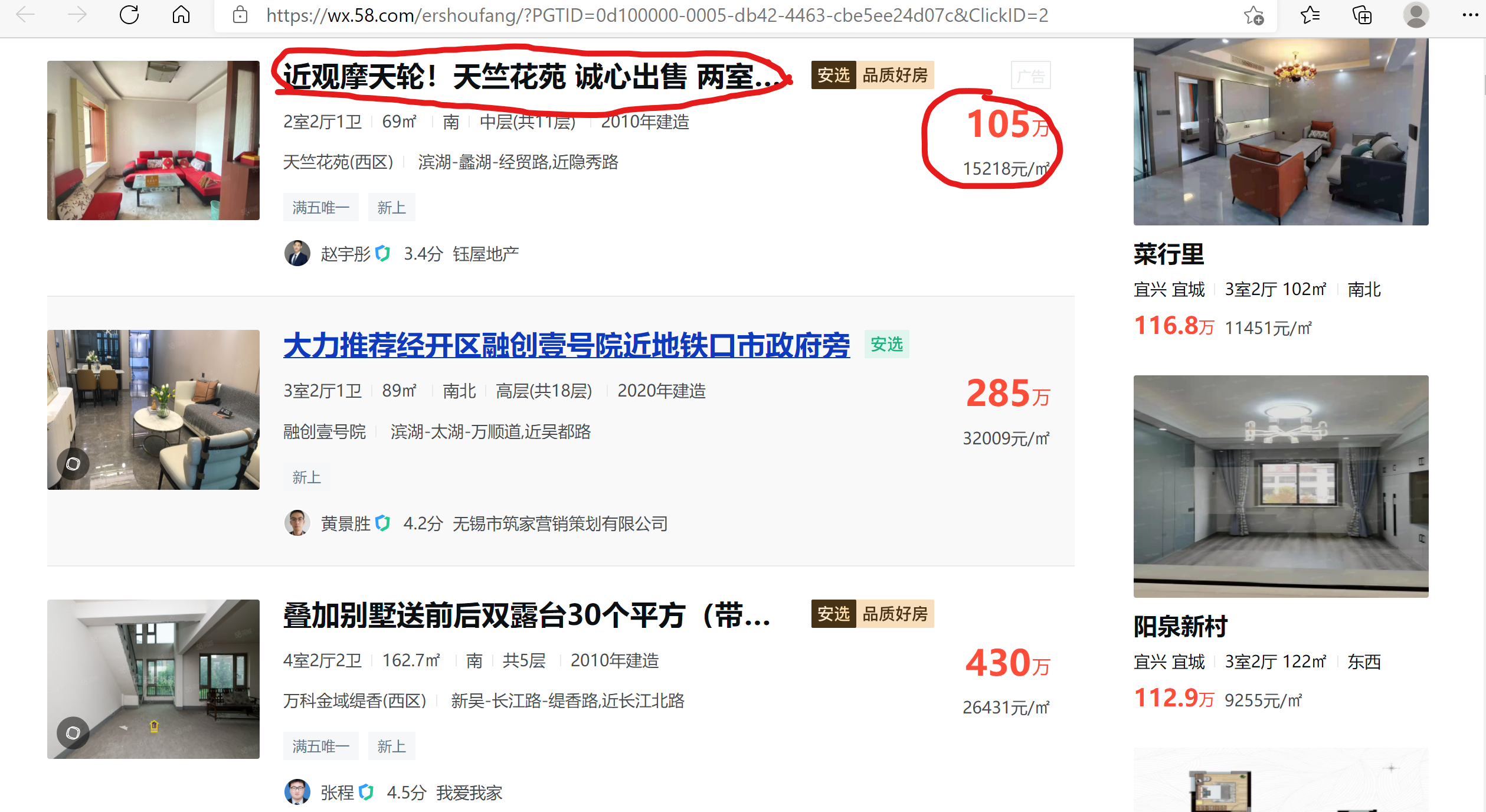
脚本:import requests
from lxml import etree
url="https://wx.58.com/ershoufang/"
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36 Edg/88.0.705.74"}
page_text=requests.get(url,headers=headers).text
tree=etree.HTML(page_text)
section_list=tree.xpath('//section[@class="list"]')
div_list=section_list[0].xpath('./div')
file=open("./58二手房.txt","w",encoding="utf-8")
for div in div_list:
title=div.xpath('./a/div[2]/div[1]/div[1]/h3/text()')[0]
print(title)
price_total=div.xpath('./a/div[2]/div[2]/p[1]//text()')
price_total="".join(price_total)
price_average=div.xpath('./a/div[2]/div[2]/p[2]/text()')[0]
file.write(title+'\t'+price_total+'\t'+price_average+'\n')
file.close()
效果图: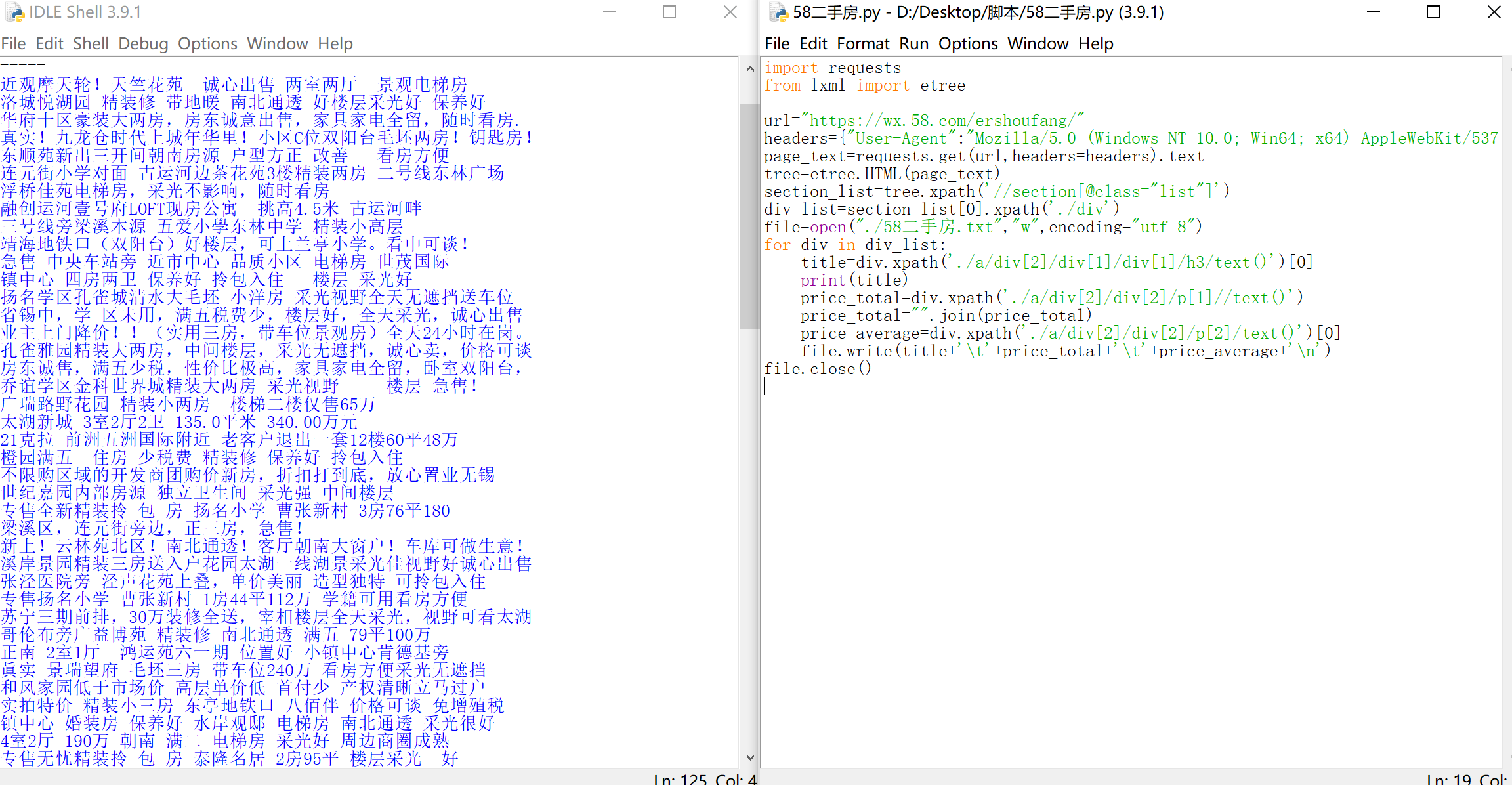
彼岸图网
需求:
爬取彼岸图网4k风景图
脚本:import requests
import os
from lxml import etree
if not os.path.exists("./4k风景"):
os.mkdir("./4k风景")
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36 Edg/88.0.705.74"}
for i in range(1,6):
if i==1:
url="http://pic.netbian.com/4kfengjing/"
else:
url="http://pic.netbian.com/4kfengjing/index_{0}.html".format(i)
response=requests.get(url,headers=headers)
page_text=response.text
tree=etree.HTML(page_text)
li_list=tree.xpath('//ul[@class="clearfix"]/li')
for li in li_list:
img_src="http://pic.netbian.com"+li.xpath('./a/img/@src')[0]
img_name=li.xpath('./a/img/@alt')[0]+".jpg"
# 解决中文乱码问题的通法
img_name=img_name.encode("iso-8859-1").decode("gbk")
img_path="./4k风景/"+img_name
img=requests.get(img_src,headers=headers).content
with open(img_path,"wb") as file:
file.write(img)
print(img_name,"下载成功...")
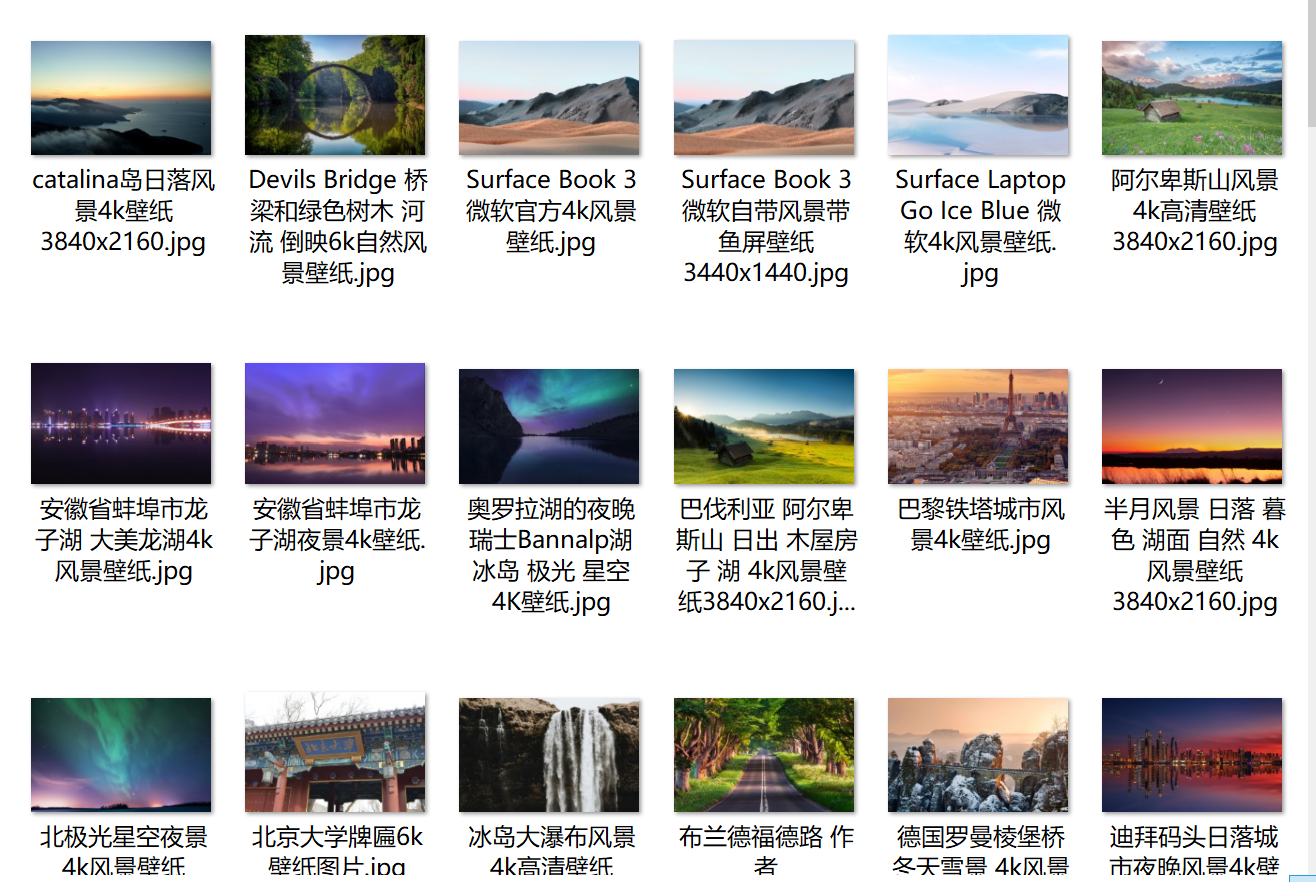
爬取效果: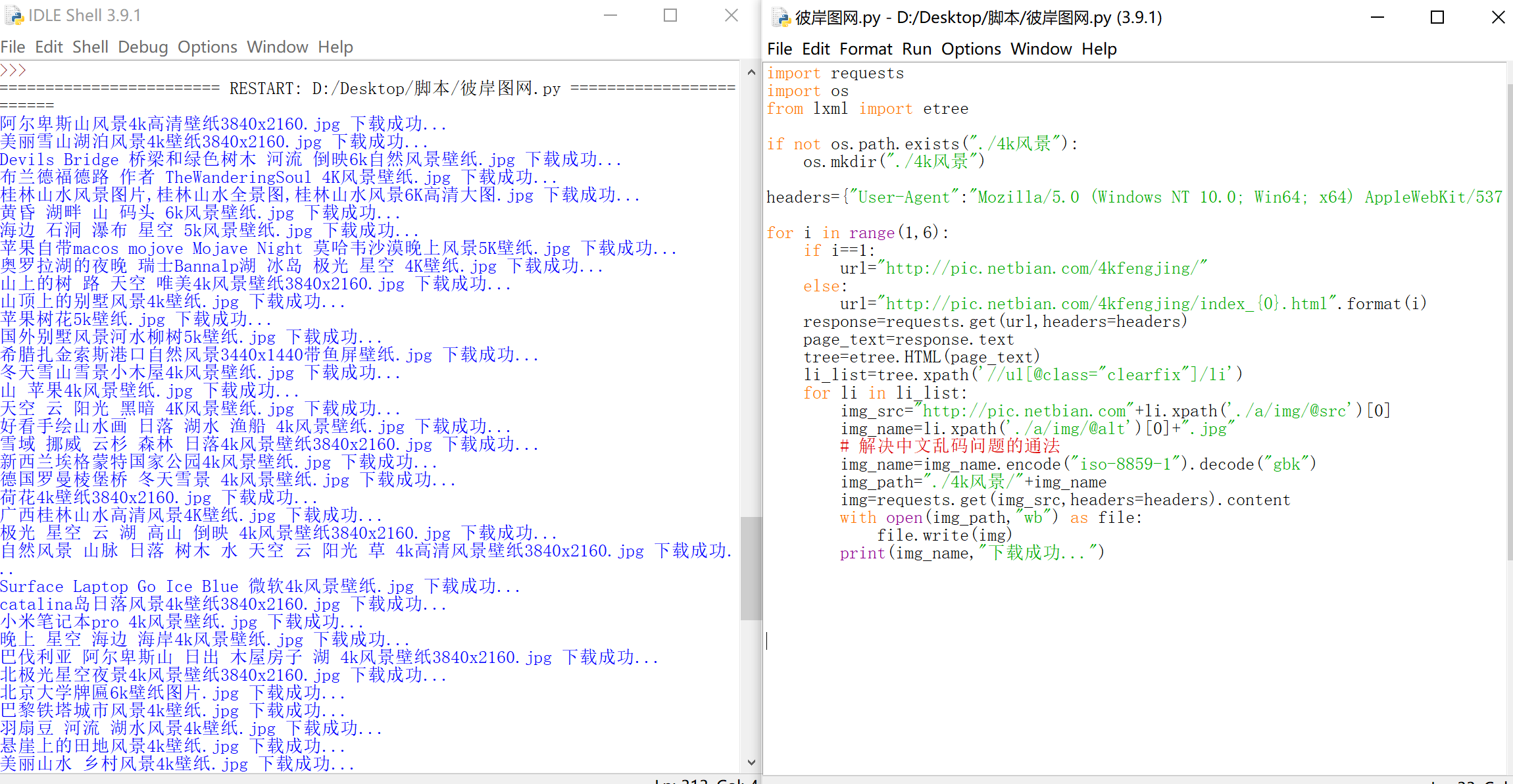
全国城市名称
需求:
爬取全国城市名称(https://www.aqistudy.cn/historydata/)
脚本:import requests
from lxml import etree
url="https://www.aqistudy.cn/historydata/"
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36 Edg/88.0.705.74"}
page_text=requests.get(url,headers=headers).text
tree=etree.HTML(page_text)
city_name=tree.xpath('//div[@class="bottom"]/ul/li/a/text() | //div[@class="bottom"]/ul/div[2]/li/a/text()')
print(city_name,len(city_name))
效果图: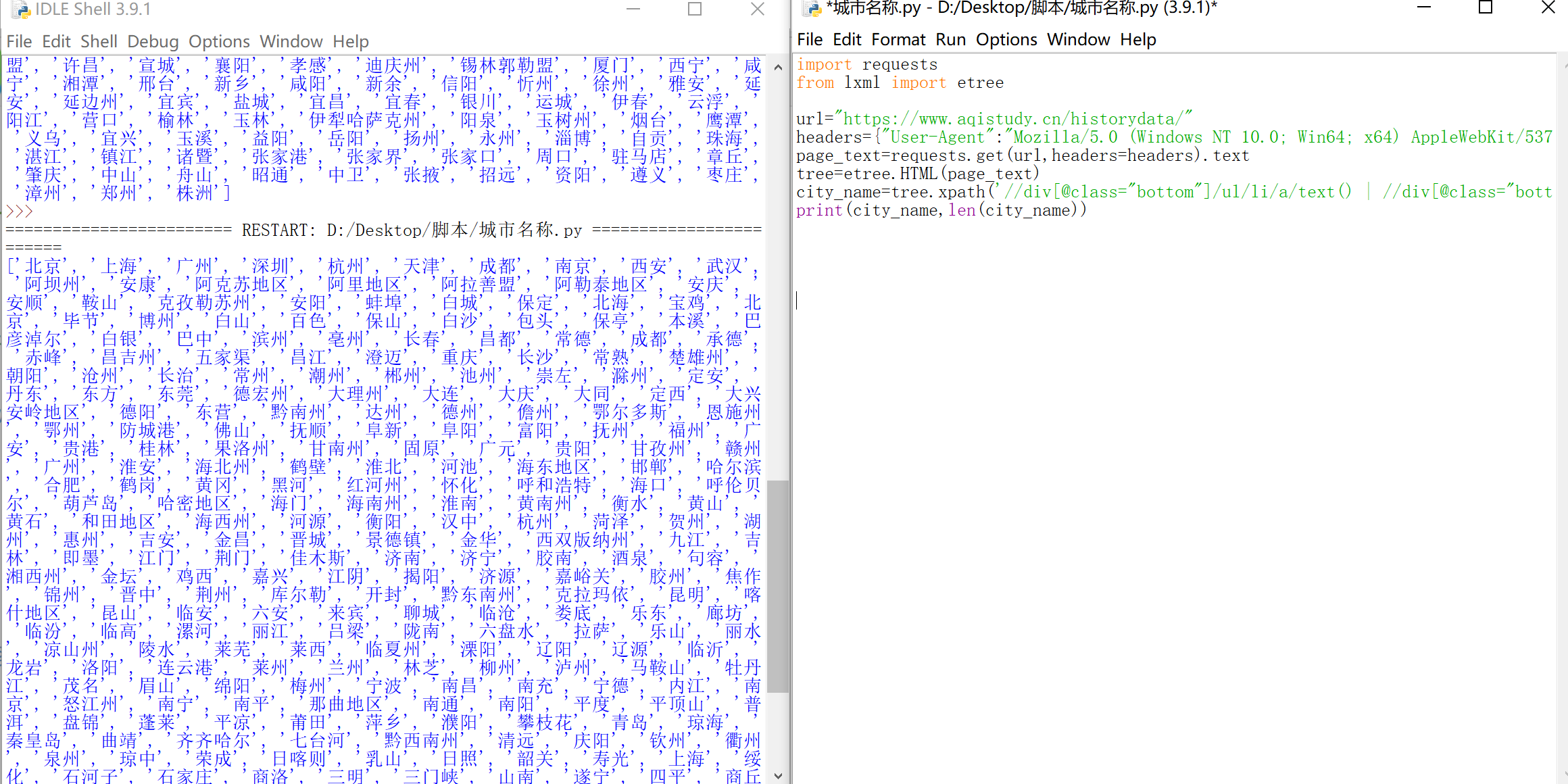
简历模板
需求:
下载站长素材中的免费简历模板(https://sc.chinaz.com/jianli/)
脚本:import requests
from lxml import etree
import os
if not os.path.exists("./简历模板"):
os.mkdir("./简历模板")
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36 Edg/88.0.705.74"}
for i in range(1,3):
if i==1:
url="https://sc.chinaz.com/jianli/index.html"
else:
url="https://sc.chinaz.com/jianli/index_{0}.html".format(i)
page_text=requests.get(url,headers=headers).text
tree=etree.HTML(page_text)
div_list=tree.xpath('//div[@class="sc_warp mt20"]/div/div/div')
for j in div_list:
href="https:"+j.xpath('./a/@href')[0]
page_text=requests.get(href,headers=headers).text
tree=etree.HTML(page_text)
download=tree.xpath('//div[@class="clearfix mt20 downlist"]/ul/li[4]/a/@href')
if len(download)==0:
continue
download=download[0]
rar=requests.get(download,headers=headers).content
rar_name=download.split("/")[-1]
rar_path="./简历模板/"+rar_name
with open(rar_path,"wb") as file:
file.write(rar)
print(rar_name,"下载成功...")
效果图: