需求:
爬取梨视频上的视频
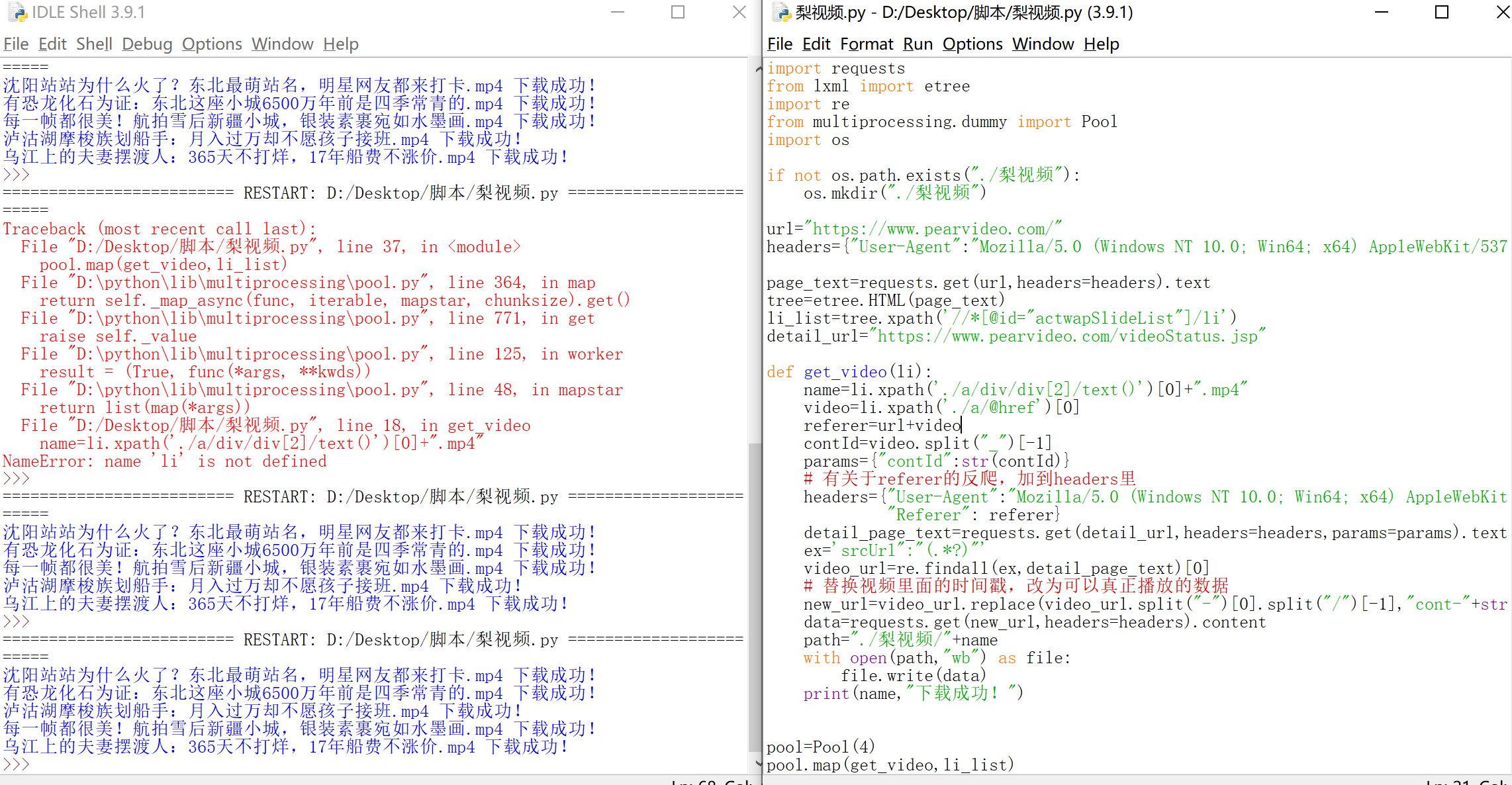
脚本:import requests
from lxml import etree
import re
from multiprocessing.dummy import Pool
import os
if not os.path.exists("./梨视频"):
os.mkdir("./梨视频")
url="https://www.pearvideo.com/"
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36 Edg/88.0.705.74"}
page_text=requests.get(url,headers=headers).text
tree=etree.HTML(page_text)
li_list=tree.xpath('//*[@id="actwapSlideList"]/li')
detail_url="https://www.pearvideo.com/videoStatus.jsp"
def get_video(li):
name=li.xpath('./a/div/div[2]/text()')[0]+".mp4"
video=li.xpath('./a/@href')[0]
referer=url+video
contId=video.split("_")[-1]
params={"contId":str(contId)}
# 有关于referer的反爬,加到headers里
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36 Edg/88.0.705.81",
"Referer": referer}
detail_page_text=requests.get(detail_url,headers=headers,params=params).text
ex='srcUrl":"(.*?)"'
video_url=re.findall(ex,detail_page_text)[0]
# 替换视频里面的时间戳,改为可以真正播放的数据
new_url=video_url.replace(video_url.split("-")[0].split("/")[-1],"cont-"+str(contId))
data=requests.get(new_url,headers=headers).content
path="./梨视频/"+name
with open(path,"wb") as file:
file.write(data)
print(name,"下载成功!")
pool=Pool(4)
pool.map(get_video,li_list)
pool.close()
pool.join()
效果图: