概述
定义:
并查集是一种树型的数据结构,用于处理一些不相交集合的合并及查询问题(即所谓的并、查)。比如说,我们可以用并查集来判断一个森林中有几棵树、某个节点是否属于某棵树等。
主要构成:
并查集主要由一个整型数组pre[ ]和两个函数find( )、join( )构成。
数组 pre[ ] 记录了每个点的前驱节点是谁,函数 find(x) 用于查找指定节点 x 属于哪个集合,函数 join(x,y) 用于合并两个节点 x 和 y 。
作用:
并查集的主要作用是求连通分支数。如果一个图中所有点都存在可达关系(直接或间接相连),则此图的连通分支数为1;如果此图有两大子图各自全部可达,则此图的连通分支数为2……
下面给出洛谷上的模板题:
P3367 【模板】并查集 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn)
find()函数的定义与实现
首先我们需要定义一个数组:int pre[1000];(数组长度依题意而定)。这个数组记录了每个节点的父节点是谁。节点从0或1开始编号(依题意而定)。比如说pre[16]=6就表示16号节点的父节点是6号。如果一个节点的父节点就是他自己,那说明他就是根节点了,查找到此结束。也有孤家寡人自成一派的,即单独一个点,那么他的父节点就是他自己。
pre数组只记录了每个节点的父节点,要想知道某个节点的祖宗节点(所在树的根节点),只能一级级查上去。因此你可以视find(x)这个函数就是找根节点用的。
下面给出这个函数的具体实现:
int find(int x) //查找节点x所在树的根节点 |
join()函数的定义与实现
如果两个集合要合并,要如何实现?要改动多少地方?其实很简单,将其中一个树挂到另一个树的根节点下即可,也就是将其中一个树的根节点的前驱设为另一个树的根节点,两个树的内部结构其实并不需要改变。join()函数的作用就是用来实现这个的。
join(x,y)的执行逻辑如下:
- 寻找 x 的所在树的根节点;
- 寻找 y 的所在树的根节点;
- 如果 x 和 y 不相等,则随便选一个树的根节点作为另一个树的根节点的父节点,如此一来就完成了 x 和 y 的合并。
下面给出这个函数的具体实现:
void join(int x, int y) |
路径压缩算法之一(优化find()函数)
问题引入:
前面介绍的 join(x,y) 实际上为我们提供了一个将不同节点进行合并的方法。通常情况下,我们可以结合着循环来将给定的大量数据合并成为若干个更大的集合(即并查集)。但是问题也随之产生,我们来看这段代码:
if(fx != fy) |
这里并没有明确谁是谁的前驱的规则,而是我直接指定后面的数据作为前面数据的前驱。那么这样就导致了最终的树状结构无法预计,即有可能是良好的 n 叉树,也有可能是单支树结构(一字长蛇形)。试想,如果最后真的形成单支树结构,那么它的效率就会及其低下(树的深度过深,那么查询过程就必然耗时)。
而我们最理想的情况就是所有人的直接上级都是根节点,这样一来整个树的结构就只有两级,此时查询根节点只需要一次。因此,这就产生了路径压缩算法。
实现:
从上面的查询过程中不难看出,当从某个节点出发去寻找它的根节点时,我们会途径一系列的节点,在这些节点中,除了根节点外,其余所有节点都需要更改直接前驱为根节点。
因此,基于这样的思路,我们可以通过递归的方法来逐层修改返回时的某个节点的直接前驱(即pre[x]的值)。简单说来就是将x到根节点路径上的所有点的pre(上级)都设为根节点。下面给出具体的实现代码:
int find(int x) |
该算法存在一个缺陷:只有当查找了某个节点的代表元后,才能对该查找路径上的各节点进行路径压缩。换言之,第一次执行查找操作的时候是实现没有压缩效果的,只有在之后才有效。
路径压缩算法之二(加权标记法)
备注:
其实它也是属于路径压缩算法,不同的是其思想更加高级(更不容易想到)罢了。
主要思路:
加权标记法需要将树中所有节点都增设一个权值,用以表示该节点所在树中的高度(比如用rank[x]=3表示 x 节点所在树的高度为3)。这样一来,在合并操作的时候就能通过这个权值的大小来决定谁当谁的上级。
在合并操作的时候,假设需要合并的两个集合的代表元分别为 x 和 y,则只需要令pre[x] = y或者pre[y] = x即可。但我们为了使合并后的树不产生退化(即:使树中左右子树的深度差尽可能小),那么对于每一个元素 x ,增设一个rank[x]数组,用以表达子树 x 的高度。在合并时,如果rank[x] < rank[y],则令pre[x] = y;否则令pre[y] = x。
举个例子,我们对以A,F为代表元的集合进行合并操作(如下图所示):
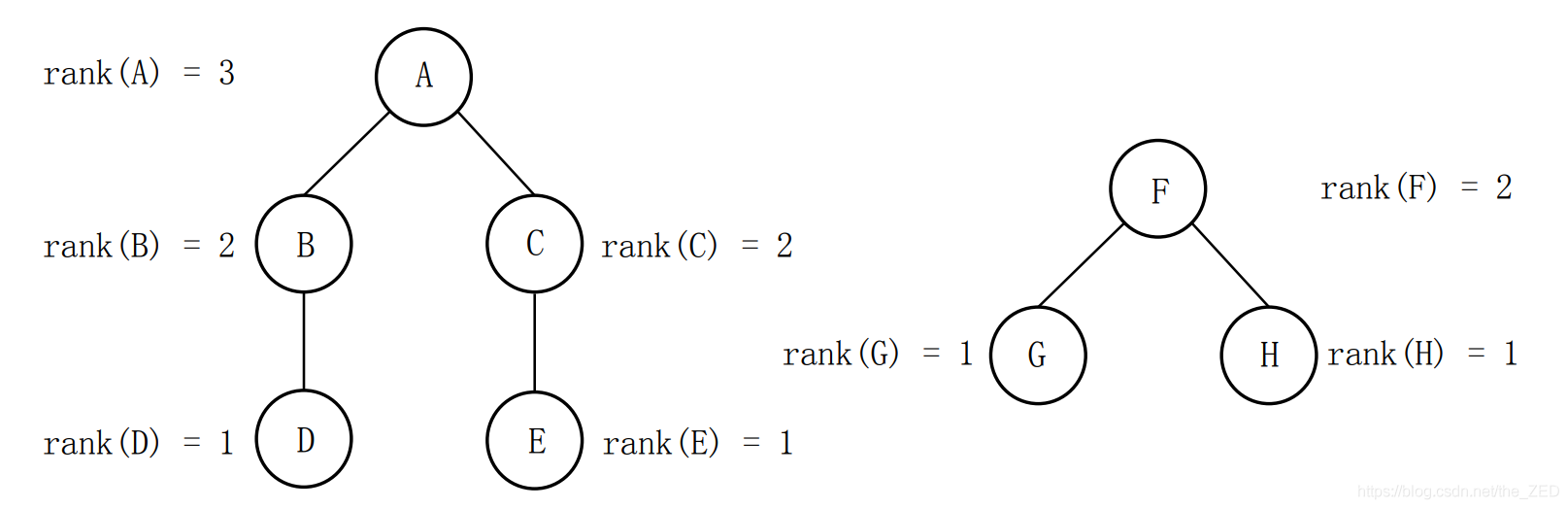
由于rank(A) > rank(F) ,因此令pre[F]= A。合并后的图形如下图所示:
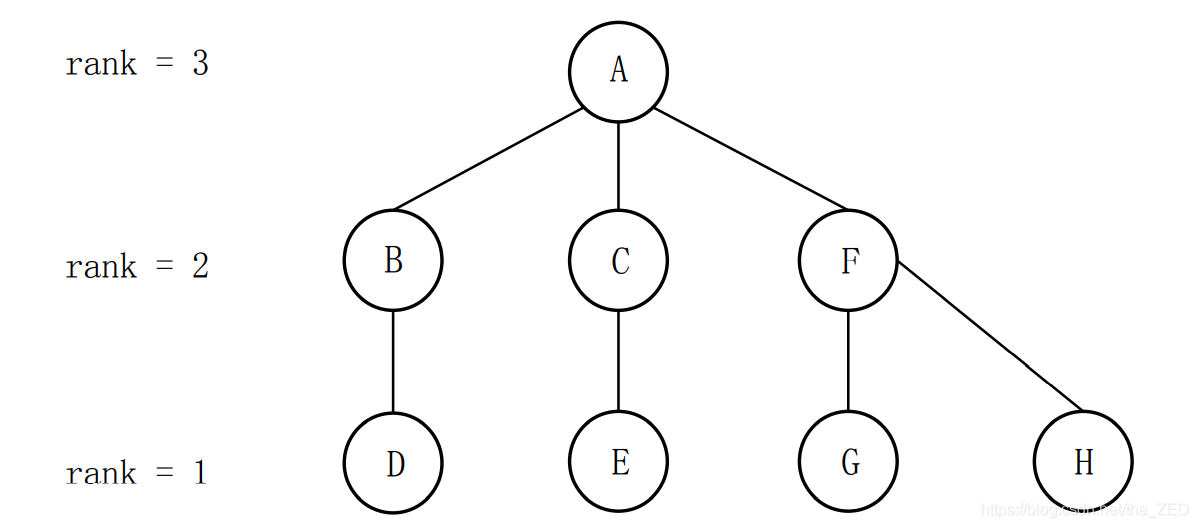
可以看出,合并前两个树的最大高度为3,合并后依然是3,这也就达到了我们的目的。但如果令pre[A]= F,那么就会使得合并后的树的总高度增加。
我们常说,鱼和熊掌不可兼得,同理,时间复杂度和空间复杂度也很难兼得。由于给每个节点都增加了一个权值来标记其在树中的高度,这也就意味着需要额外的数据结构来存放权重信息,所以这将导致额外的空间开销。
实现:
加权标记法的核心在于对rank数组的逻辑控制,其主要的情况有:
- 如果rank[x] < rank[y],则令pre[x] = y;
- 如果rank[x] == rank[y],则可任意指定上级;
- 如果rank[x] > rank[y],则令pre[y] = x;
在实际写代码时,为了使代码尽可能简洁,我们可以将第1点单独作为一个逻辑选择,然后将2、3点作为另一个选择(反正第2点任意指定上级嘛),所以具体的代码如下:
void join(int x, int y) |
总结
1、用集合中的某个元素来代表这个集合,则该元素称为此集合的代表元;
2 、一个集合内的所有元素组织成以代表元为根的树形结构;
3 、对于每一个元素 x,pre[x] 存放 x 在树形结构中的父亲节点(如果 x 是根节点,则令pre[x] = x);
4 、对于查找操作,假设需要确定 x 所在的的集合,也就是确定集合的代表元。可以沿着pre[x]不断在树形结构中向上移动,直到到达根节点。
因此,基于这样的特性,并查集的主要用途有以下两点:
- 维护无向图的连通性(判断两个点是否在同一连通块内,或增加一条边后是否会产生环);
- 用在求解最小生成树的Kruskal算法里。
一般来说,一个并查集对应三个操作:
- 初始化( Init()函数 )
- 查找函数( Find()函数 )
- 合并集合函数( Join()函数 )
下面给出代码汇总:
|
本篇博客基于以下博客进行了简化,并加入了自己的理解:








